In our “Engineering Energizers” Q&A series, we spotlight the engineering leaders transforming data management at Salesforce. Today, we feature Meghamala Ulavapalle, who leads the Unstructured Data Services (UDS) team within Data Cloud. Her team specializes in converting unstructured data into a valuable resource for AI-driven insights, personalized customer experiences, and automated decision-making.
Following the launch of Agentforce at Dreamforce 2024, Meghamala’s team helped scale unstructured data capabilities 3x— enabling fast, reliable ingestion and real-time search across millions of files. This new high-throughput, low-latency service is now a foundational layer of Data Cloud’s AI ecosystem.
Discover how her team eliminated costly data movement with Zero Copy for external data stores, optimized high-throughput indexing for millions of files, and developed scalable normalization strategies for various file types, all while pushing the boundaries of what’s possible in Data Cloud.
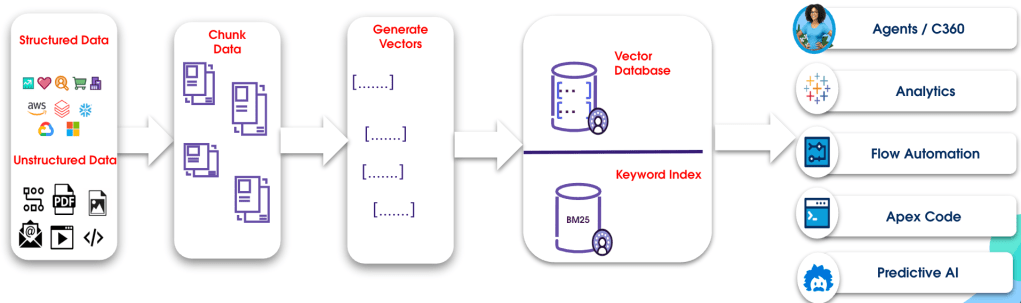
Unstructured data in action.
What is your team’s mission, and how does it support unstructured data ingestion and search indexing within Data Cloud?
The team is dedicated to helping our customers unlock the full potential of their unstructured data within Data Cloud. We believe data is essential for creating personalized experiences, driving analytics, and enabling automation.
Unstructured data, which makes up about 80% of customer information, comes in various formats like audio, video, and documents. Processing this data can be complex and challenging. To address these issues, the team is developing advanced capabilities within Data Cloud to seamlessly ingest, index, and search this diverse data.
These newly built capabilities form the backbone of the infrastructure powering Agentforce, enabling fast, scalable access to unstructured content for intelligent agents and real-time experiences. By making unstructured data searchable and indexable, we ensure it can be used in AI models that enhance personalized interactions and drive intelligent decision-making across the platform.
What’s the toughest ingestion bottleneck your team encountered, and what engineering changes helped eliminate it?
Managing large volumes of unstructured customer data across multiple external systems is a significant challenge. Traditional methods of copying this data into Data Cloud are inefficient and costly. To address this, the team developed the Zero Copy solution for external data stores. This solution allows Data Cloud to directly access customer data in existing cloud storage systems like AWS S3, Azure Blob Storage, and Google Cloud Storage without moving or duplicating files.
By leveraging the native file notification capabilities of these blob stores, customers can configure their storage buckets to notify Data Cloud of any new, updated, or deleted files. This design supports near real-time data ingestion, reduces latency, cuts data transfer costs, and simplifies setup by using existing infrastructure.
The team also created a direct ingestion path for Salesforce file attachments, eliminating the need to move these files to external blob stores. Support was extended to other common enterprise platforms, including Google Drive, SharePoint, Confluence, and Sitemaps, ensuring a seamless and efficient data pipeline for various customer use cases.
When handling millions of unstructured files, what was your biggest failure point in indexing, and how did you rebuild around it?
Scaling the indexing pipeline to manage millions of unstructured files posed a major challenge, particularly in generating embeddings with low latency. Converting diverse text and media into numerical vectors using machine learning models is a computationally intensive task.
Initially, the team faced frequent job timeouts, failures, and long processing times. To tackle these issues, they moved embedding tasks to high-performance computing environments, using instances with more CPU power and selectively leveraging GPUs. This shift dramatically increased throughput and minimized job failures.
They then optimized Apache Spark jobs, which are crucial for distributed processing. By improving data partitioning, minimizing shuffle operations, and fine-tuning resource allocation, they enhanced the performance of their existing infrastructure.
Lastly, while dealing with embedding models, the team adopted a dynamic approach. They chose to inline the embedding models for straightforward, low-latency requirements but made batched calls to hosted services when cutting-edge models were involved. This strategy effectively reduced both latency and costs.
What’s been your hardest challenge in normalizing diverse file types without degrading search quality?
Handling the normalization of a vast array of file types in Data Cloud was a major technical obstacle. The team needed a scalable way to process everything from text documents such as PDFs and Word files to audio, video, and images, without creating individual pipelines for each format.
To overcome this, they created a powerful normalization layer that could extract useful textual content and metadata from different file types. For text documents, this layer managed various encodings and extracted structured text while keeping important formatting intact. For audio and video files, the focus was on precise transcription and capturing essential metadata. For images, they used optical character recognition (OCR) to pull out any embedded text and image captioning models to generate descriptive text.
To enhance the accuracy of its Retrieval Augmented Generation (RAG) pipelines, the team implemented flexible chunking strategies for the normalized content. For text documents, the content was split by paragraphs in some cases and by the number of tokens in others. Audio files were divided by speaker turns and images were chunked using their captions. This method ensures high search accuracy by preserving the unique attributes of each content type.
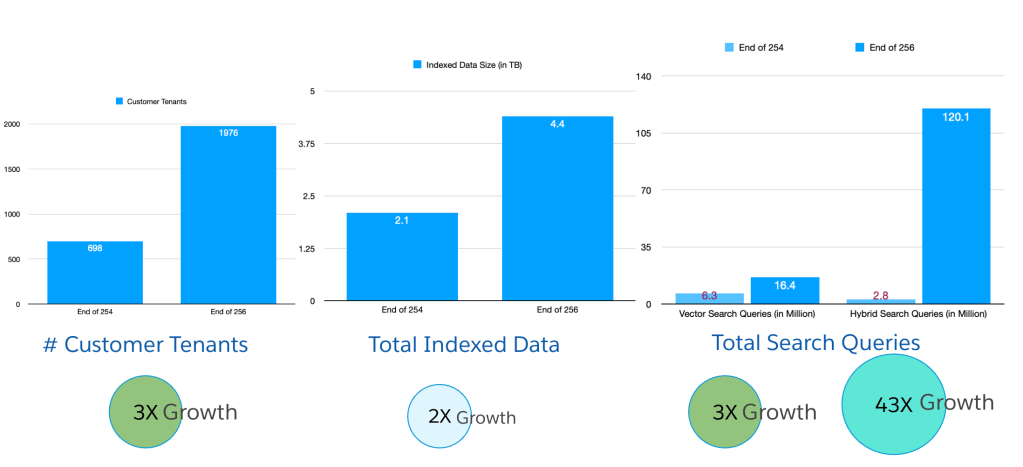
Unstructured Data Services growth across releases.
As enterprise customers ingest data simultaneously, what scaling or concurrency issues pushed your system to the edge?
The explosive 3x growth in unstructured data capabilities after the Agentforce announcement at Dreamforce 2024 exposed significant scalability issues. One key problem was the creation of numerous small search indexes by smaller tenants, mostly from trials and demos. Although the data volume per tenant was relatively low, the high number of concurrent indexing and querying operations put a strain on the system. Initially, the team tackled this by increasing resources in Kubernetes clusters, but this led to a substantial rise in costs.
The original architecture used long-running Spark streaming jobs for each tenant, which worked well for continuous data streams but was inefficient for smaller tenants with sporadic updates. To address this, the team introduced an on-demand Spark streaming model, where jobs are only initiated when new data is available. This change cut the cluster total spend (CTS) by almost 50%.
For larger enterprise customers, the challenge was different. They needed to process vast amounts of data, which required dynamic resource allocation within Kubernetes and enhanced fault tolerance. The Vector Database also faced concurrency issues, leading to efforts to optimize data structures and caching mechanisms to minimize the need for raw hardware scaling.
How did your team rethink indexing architecture to prepare for the next 10x growth without sacrificing reliability?
Preparing the indexing architecture for the next 10x growth has been a proactive effort, not a reactive one. After managing an initial 10x surge in adoption, the team identified key areas for ongoing investment to ensure stability, reliability, usability, and cost-efficiency as demand continues to grow.
A central part of this strategy is maximizing resource efficiency. The team is optimizing Kubernetes and Spark by implementing advanced resource scheduling, workload isolation, and fine-tuned autoscaling. These measures aim to reduce cost growth as data volumes increase. They are also investing in data processing pipelines for both large batch jobs and incremental streaming updates, ensuring that the system can scale without a linear increase in resource requirements.
In addition to backend improvements, the team is enhancing the user experience by simplifying index creation with a more intuitive UI and robust APIs for seamless integration with upstream and downstream systems. Additionally, they are prioritizing observability by adding real-time monitoring, detailed logs, and comprehensive metrics to improve visibility into the pipeline.
The team is also building support for real-time indexing and embracing extensibility. This allows customers to bring their own code and models for highly specialized use cases, ensuring that the platform can meet a wide range of needs.



