There is growing evidence that we are experiencing a huge bubble when it comes to AI. But what’s also weird, bordering on cultish, is how bought in the researchers are in the world of AI.
There’s something called the AI Futures Project. It’s a series of blog posts about trying to predict various aspects of how soon AI is going to be just incredible. For example, here’s a graph of different models for how long it will take until AI can code like a superhuman:
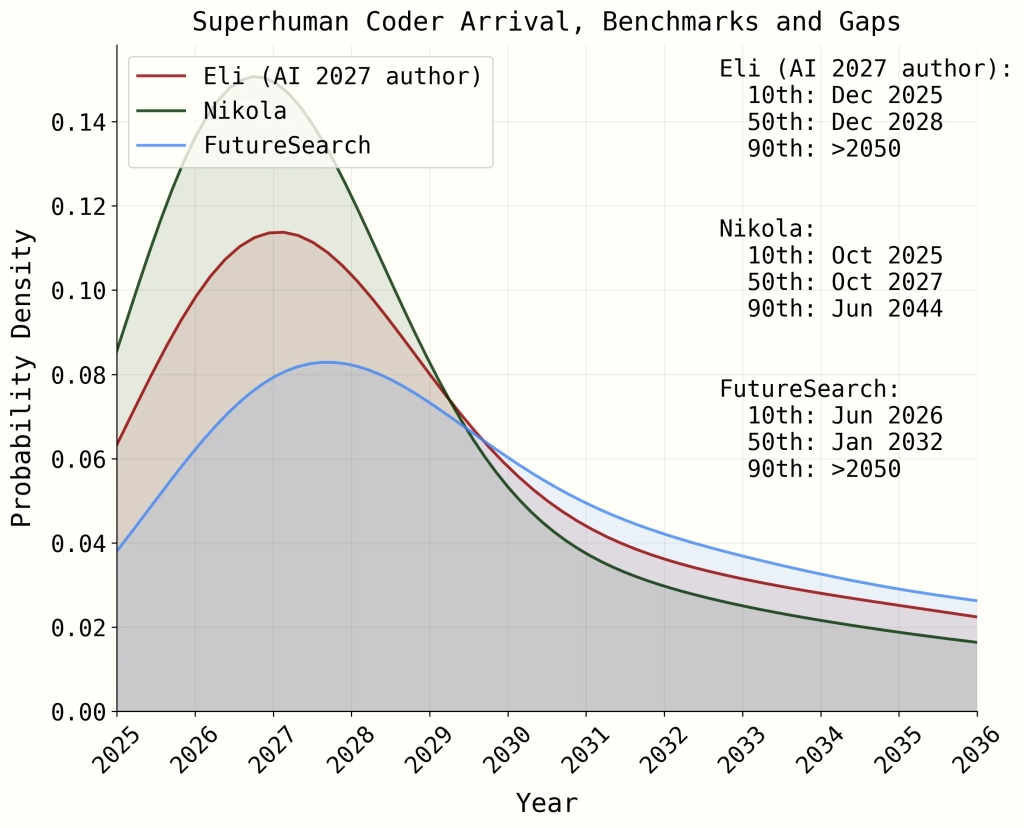
Doesn’t this remind you of the models of COVID deaths that people felt compelled to build and draw? They were all entirely wrong and misleading. I think we did them to have a sense of control in a panicky situation.
Here’s another blogpost of the same project, published earlier this month, this time imagining a hypothetical LLM called OpenBrain, and what it’s doing by the end of this year, 2025:
… OpenBrain’s alignment team26 is careful enough to wonder whether these victories are deep or shallow. Does the fully-trained model have some kind of robust commitment to always being honest? Or will this fall apart in some future situation, e.g. because it’s learned honesty as an instrumental goal instead of a terminal goal? Or has it just learned to be honest about the sorts of things the evaluation process can check? Could it be lying to itself sometimes, as humans do? A conclusive answer to these questions would require mechanistic interpretability—essentially the ability to look at an AI’s internals and read its mind. Alas, interpretability techniques are not yet advanced enough for this.
The wording above makes me roll my eyes, for three reasons.
First, there is no notion of truth in an LLM, it’s just predicting the next word based on patterns in the training data (think: Reddit). So it definitely doesn’t have a sense of honesty or dishonesty. So that’s a nonsensical question, and they should know better. I mean, look at their credentials!
Second, the words they use to talk about how it’s hard to know if it’s lying or telling the truth betray the belief that there is a consciousness in there somehow but we don’t have the technology yet to read its mind: “interpretability techniques are not yet advanced enough for this.” Um, what? Like we should try harder to summon up fake evidence of consciousness (more on that in further posts)?
Thirdly, we have the actual philosophical problem that *we* don’t even know when we are lying, even when we are conscious! I mean, people! Can you even imagine having taken an actual philosophy class? Or were you too busy studying STEM?
To summarize:
Can it be lying to itself? No, because it has no consciousness.
But if it did, then for sure it could be lying to itself or to us, because we could be lying to ourselves or to each other at any moment! Like, right now, when we project consciousness onto the algorithm we just built with Reddit training data!



